Coding like we left the stone age
It has been three-ish years since I last uttered public musings (5 years since I longformed) about how we can unstuck ourselves from the textual coding pit we find ourselves in. And it has not been for a lack of musing! I am well aware of coders' (makers’?) bias to release too late, but I thought I had adjusted for it, and was going to release just on time. Worse yet, I’m also a man, a primate historically (biologically? (culturally? (computationally?))) bad at asking for feedback. Well, here it is:
Previously on Breaking Text
A lot has happened in these past years, for me personally, but also in the
future of coding space. First of all, the term itself is new!
A blossoming community of loosely-connected
makers has gathered around it that works on both imaging and building the
future. Two vision-adjacent projects I learned about, through that community,
are Dark and Dion;
both exploring structured editing in the context of new programming languages.
Now this is also where my current endeavour diverges, as I am building fluid structured
editing in the context of an existing language: JavaScript. My reasons are two-fold:
there is only so much I can achieve in my fairly limited side-project time and I
believe in the power of a limited scope for quicker discovery of which ideas have
legs (for some definition of quicker, 5 years and all).
The code editor space has also seen a refresh, with VSCode eating the world of eating the world. I would argue this change of guards has done little for the core editing experience, with it being a mostly a re-run of popular bangers like multi-cursor, a command palette and many more. Where VSCode and Microsoft at large have excelled is getting developers more in touch with their tools by turning it into a vibrant, extremely extensible, open project with its maintainers working like machines.
On top of that they gave rise to the language-server-protocol for solving the n:m editor-to-language problem of providing IDE prowess, rivalling the Goliath of structured refactor, IntelliJ. And while it makes some feel grumpy(er?), there is no denying its strategic finesse in channeling efforts from disparate groups to give rise to more high-level tooling for more editors, with basically all editors around having mature LSP-support.
With VSCode’s dominance growing, my project’s direction has also changed. While
I was entertaining the idea of building my own code editor for some of these
last years, my great friend Reuben, gave me
the decisive nudge to at least investigate prototyping a VSCode extension.
Various people before have given me similar nudges in the past, but I was too
married to the potential of ideas in the space of “make JavaScript look like
Python”, for which I’d need more control over the editor.
This is a key learning, that I might have to keep re-learning: Talk to your peers,
and really listen, entertain their ideas as if they are your own, especially if
they are conflicting with some of your assumptions. Super fucking hard at times,
but it can be that critical push, which it was for me.

What’s Tofu now?
Tofu is a code editing extension for VSCode which makes keystrokes more meaningful by outsourcing the nuisance of code formatting to Prettier, and actually running it after ever change. That frees up your keys to trigger more meaningful, contextually relevant, actions.
Pictures are worth a thousand words, hence you should check out my
thread over on Mastodon which is
worth roughly 30FPS * 1k = 30,000 words (per second!) of demonstrating the
core interaction model.
I have been using Tofu as my main editor for a few months now and it feels much more natural, effective and aligned with my mental model of code. Going back to coding without it feels like eating soup with a fork. Tofu is a spoon! (Well, maybe a spork, I've got a sludge of other ideas I'm still missing when coding.)
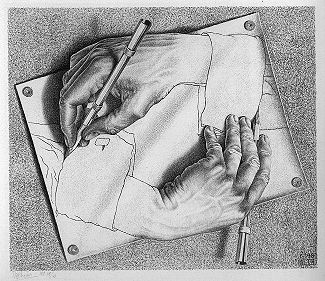
A dream I have always carried with me, possibly incepted by my own mother when
she showed me "Drawing Hands" by M. C. Escher in my childhood, is to use a tool
to work on the tool itself. Thus it has been deeply gratifying to build Tofu
with Tofu and just press Cmd+R to immediately use what I've built (I have VSCode
to thank for the great extension DX).
The singularity I look forward to is the one where we programmers (and preferably
that group includes a more diverse group of people than it does now) are constantly
reshaping the authoring environment we use, thus gifting ourselves greater powers
which we use to further reshape it, triggering a virtuous cycle.
One thing that is not shown in the Mastodon thread, which I, for now, consider to be a key feature is the, very literal, ESCape hatch. The commandment of semantic transformation is merely inferred from the axiom “Find the most direct path from intention to change” and as long as there are enough situations where a syntactically invalid / textual transformation is faster (or more intuitive), Tofu needs to have an escape hatch for falling back to text. I will go into that more in the Operating in the Face of Errors section.
Saul not (yet) Goodman
I hope you are not tired of Breaking Bad references already.
One should be able to make scrambled tofu without breaking a few eggs, but unfortunately for now there are caveats:
The Role of Speed
Some of my best friends are VIM and CLI wizards (I am still looking for emacs friends, call me!). Yet my philosophy is different, I barely mind that IntelliJ asks me to sacrifice a goat in a bonfire of RAM. As long as it spares me the pain of repetitive error-prone string-based actions, I’d gladly sacrifice my whole village for it (Aside, since I’m talking about IntelliJ: It’s a great way to enjoy the concepts of Git, without suffering through its CLI).
In a similar vein, Tofu’s tenet is to be more
effective at semantic code changes, not to reach
keystroke-to-screen time parity
anytime soon, or even be on par with our decadent Electron editors. In its
current form, it is not performant. I do not think there are fundamental
roadblocks in achieving efficiency and I am interested in investigating ideas of
solving it. But effectivity is my research priority right now.
I am infinitely more interested in code editing paradigms which are more effective
now and can be made efficient later, than our current gods of meticulously
optimized char buffers. You can not optimize your way to a higher level of abstraction.
On my 2019 MacBook Pro it is fast enough to be my main driver, as long as I keep my files below ~500 LOC. This is slightly above my natural limit for what I consider to be a manageable file size, but maybe that's my Stockholm syndrome talking.
Here is the major bottleneccc: Tofu uses Babel to re-parse the entire file after each keystroke. What kind of monster would do that? The kind of monster who builds on Babel’s, fairly semantic, AST and who needs Prettier, which also operates on Babel’s AST. I learned that syntax trees exist on a spectrum from concrete to semantic (not to speak of other dimensions) where Babel’s structure lends itself excellently to building the kind of semantic transformations I want to build, likely owing to its inception as a tool for transpilation (just another kind of semantic transformation). Additionally it comes with great TypeScript typings which are a lifesaver.
Again, these problems are solvable. The ecosystem is as alive as ever, and is churning out new parsers by the minute.
- TreeSitter, an incremental parsing system, used In VSCode for syntax highlighting, would be fast enough and is a prime candidate. Since Tofu leans heavily on prettier, an AST compatibility layer would need to be added.
- Rome, while not incremental, does come with its own formatter, and might be fast enough as well. It’s freshly off the press and I did not manage to get its alpha Node API to work just yet, but I’ll keep trying.
Another option would be to work on my own parser. While I do like reading papers and blog posts about clever parser engineering feats, I would prefer playing lego with pre-existing projects and focus my energy on the meat of Tofu.
Operating in the Face of Errors
There is another good reason to switch to one of these parsers: They come with error recovery. That means you could have syntactically invalid steps in your code modification sequence, while still being able to use structural features (to a degree).
Currently when you have an unrecoverable syntax error (I implicitly lied before,
Babel does have some error recovery), Tofu’s shortcuts get disabled and
you’re back in vanilla VSCode text editing mode (You can also enter this state
by hitting Esc).
I still find the transition a bit jarring and am in general not a fan of having different
modes. Is there a way around it? Error-tolerant parsers would help a lot, but maybe
an escape hatch is always needed? Tim Sweeney popped into my Twitter thread from
a few years ago and made an astute observation about this:
The sanity of this approach depends on how much of editing is making a transition from one valid code state to another through a series of invalid states, where a uniform text editor handles that more gracefully.
— Possibly Tim Sweeney (@TimSweeneyEpic) June 3, 2019
Back then I replied with what I still believe today: Most transformations are
better made structurally (better meaning either fewer keystrokes or a more
direct mental model, and often both). I also extended an invitation, which still
stands, to send code modifications my way where textual beats structurally on
those terms.
I still expect there to be some residual transformations which are better made in
text but my hope (or confirmation bias, you pick) is that once the 99% is neatly
handled, you will prefer not to break modes and enter text-land, even in the 1% of
cases.
Ambiguities
This is where text usually shines, and where Tofu has to make some decisions.
One simple example, where text does not shine and which JS veterans will be familiar with is adding an expression followed by a parenthesized expression on the next line. If you forget the semicolon, you have created a hidden call expression.
foo
((n) => n * 2)(21);
Prettier saves you from that misery of accidental calls, by gluing the call expression together, thus making your mistake visible.
foo((n) => n * 2)(21);
Since Tofu relies on Prettier and aims to get your intention right, it inserts a semicolon when you type on a new line:
foo;
((n) => n * 2)(21);
Another ambiguity I have not yet solved for are < and >. When you select an
expression and hit < you wrap it in JSX and with > in an arrow function.
This stands in contrast to | and & which wrap the current selection in
logical expressions, so one might expect < and > to do the same with binary
expressions aka comparisons.
Now I've simply needed that less, and there is another way to add binary/logical
expressions, but I am still displeased by the inconsistency. I think a QuickFix-widget
like piece of UI, asking to disambiguate will be the solution here.
Fundamentally I believe these kinds of issues are solvable, with a number of context-specific rules.
WYTINWYT (What you type is not what you get)
There is an argument to be made that typing out what you have in mind becomes harder, when you have to wait after each keystroke to see what your editor turns it into. I'd wager this is nullified when, what your editor does, is predictable and sensible. Raw text input is the simplest thing your editor can do, and thus not much has to be learned.
Then again, as Tofu's creator, I have all of the rules in my mind already, so I
have not experienced the learning curve of the approach. Recently I've added a
spread-completion, where starting a new element in a collection with a dot (.)
automatically inserts a spread element (...a) and I have noticed myself still
hitting the dot three times. So it does take some time for new rules to be
ingested.
I believe the learning curve to be worth it, but I am sure opinions will differ on this one.
El camino a seguir
Half of the post is caveats, not because I am not a fervent believer in the approach, but because I believe there is some distance between the status quo and this paradigm, and then there is also some distance between what this iteration is and what it could be.
So far prioritization has been guided by my own needs, and I am sure that I've gotten used to some of Tofu's rougher edges. I could benefit from more outside input on where it helps or hurts.
Thus, go forth, give Tofu a try for your next side project, report issues and let me know what you think.